Posted by tombennet
Practitioners of SEO have always been mistrustful of JavaScript.
This is partly based on experience; the ability of search engines to discover, crawl, and accurately index content which is heavily reliant on JavaScript has historically been poor. But it’s also habitual, born of a general wariness towards JavaScript in all its forms that isn’t based on understanding or experience. This manifests itself as dependence on traditional SEO techniques that have not been relevant for years, and a conviction that to be good at technical SEO does not require an understanding of modern web development.
As Mike King wrote in his post The Technical SEO Renaissance, these attitudes are contributing to “an ever-growing technical knowledge gap within SEO as a marketing field, making it difficult for many SEOs to solve our new problems”. They also put SEO practitioners at risk of being left behind, since too many of us refuse to explore – let alone embrace – technologies such as Progressive Web Apps (PWAs), modern JavaScript frameworks, and other such advancements which are increasingly being seen as the future of the web.
In this article, I’ll be taking a fresh look at PWAs. As well as exploring implications for both SEO and usability, I’ll be showcasing some modern frameworks and build tools which you may not have heard of, and suggesting ways in which we need to adapt if we’re to put ourselves at the technological forefront of the web.
1. Recap: PWAs, SPAs, and service workers
Progressive Web Apps are essentially websites which provide a user experience akin to that of a native app. Features like push notifications enable easy re-engagement with your audience, while users can add their favorite sites to their home screen without the complication of app stores. PWAs can continue to function offline or on low-quality networks, and they allow a top-level, full-screen experience on mobile devices which is closer to that offered by native iOS and Android apps.
Best of all, PWAs do this while retaining – and even enhancing – the fundamentally open and accessible nature of the web. As suggested by the name they are progressive and responsive, designed to function for every user regardless of their choice of browser or device. They can also be kept up-to-date automatically and — as we shall see — are discoverable and linkable like traditional websites. Finally, it’s not all or nothing: existing websites can deploy a limited subset of these technologies (using a simple service worker) and start reaping the benefits immediately.

The spec is still fairly young, and naturally, there are areas which need work, but that doesn’t stop them from being one of the biggest advancements in the capabilities of the web in a decade. Adoption of PWAs is growing rapidly, and organizations are discovering the myriad of real-world business goals they can impact.
You can read more about the features and requirements of PWAs over on Google Developers, but two of the key technologies which make PWAs possible are:
App Shell Architecture: Commonly achieved using a JavaScript framework like React or Angular, this refers to a way of building single page apps (SPAs) which separates logic from the actual content. Think of the app shell as the minimal HTML, CSS, and JS your app needs to function; a skeleton of your UI which can be cached.
Service Workers: A special script that your browser runs in the background, separate from your page. It essentially acts as a proxy, intercepting and handling network requests from your page programmatically.
Note that these technologies are not mutually exclusive; the single page app model (brought to maturity with AngularJS in 2010) obviously predates service workers and PWAs by some time. As we shall see, it’s also entirely possible to create a PWA which isn’t built as a single page app. For the purposes of this article, however, we’re going to be focusing on the ‘typical’ approach to developing modern PWAs, exploring the SEO implications — and opportunities — faced by teams that choose to join the rapidly-growing number of organizations that make use of the two technologies described above.
We’ll start with the app shell architecture and the rendering implications of the single page app model.
2. The app shell architecture
URLs
In a nutshell, the app shell architecture involves aggressively caching static assets (the bare minimum of UI and functionality) and then loading the actual content dynamically, using JavaScript. Most modern JavaScript SPA frameworks encourage something resembling this approach, and the separation of logic and content in this way benefits both speed and usability. Interactions feel instantaneous, much like those on a native app, and data usage can be highly economical.

Credit to https://developers.google.com/web/fundamentals/architecture/app-shell
As I alluded to in the introduction, a heavy reliance on client-side JavaScript is a problem for SEO. Historically, many of these issues centered around the fact that while search crawlers require unique URLs to discover and index content, single page apps don’t need to change the URL for each state of the application or website (hence the phrase ‘single page’). The reliance on fragment identifiers — which aren’t sent as part of an HTTP request — to dynamically manipulate content without reloading the page was a major headache for SEO. Legacy solutions involved replacing the hash with a so-called hashbang (#!) and the _escaped_fragment_ parameter, a hack which has long-since been deprecated and which we won’t be exploring today.
Thanks to the HTML5 history API and pushState method, we now have a better solution. The browser’s URL bar can be changed using JavaScript without reloading the page, thereby keeping it in sync with the state of your application or site and allowing the user to make effective use of the browser’s ‘back’ button. While this solution isn’t a magic bullet — your server must be configured to respond to requests for these deep URLs by loading the app in its correct initial state — it does provide us with the tools to solve the problem of URLs in SPAs.
// Run this in your console to modify the URL in your
// browser – note that the page doesn’t actually reload.
history.pushState(null, “Page 2”, “/page2.html”);
The bigger problem facing SEO today is actually much easier to understand: rendering content, namely when and how it gets done.
Rendering content
Note that when I refer to rendering here, I’m referring to the process of constructing the HTML. We’re focusing on how the actual content gets to the browser, not the process of drawing pixels to the screen.
In the early days of the web, things were simpler on this front. The server would typically return all the HTML that was necessary to render a page. Nowadays, however, many sites which utilize a single page app framework deliver only minimal HTML from the server and delegate the heavy lifting to the client (be that a user or a bot). Given the scale of the web this requires a lot of time and computational resource, and as Google made clear at its I/O conference in 2018, this poses a major problem for search engines:
“The rendering of JavaScript-powered websites in Google Search is deferred until Googlebot has resources available to process that content.”
On larger sites, this second wave of indexation can sometimes be delayed for several days. On top of this, you are likely to encounter a myriad of problems with crucial information like canonical tags and metadata being missed completely. I would highly recommend watching the video of Google’s excellent talk on this subject for a rundown of some of the challenges faced by modern search crawlers.
Google is one of the very few search engines that renders JavaScript at all. What’s more, it does so using a web rendering service that until very recently was based on Chrome 41 (released in 2015). Obviously, this has implications outside of just single page apps, and the wider subject of JavaScript SEO is a fascinating area right now. Rachel Costello’s recent white paper on JavaScript SEO is the best resource I’ve read on the subject, and it includes contributions from other experts like Bartosz Góralewicz, Alexis Sanders, Addy Osmani, and a great many more.
For the purposes of this article, the key takeaway here is that in 2019 you cannot rely on search engines to accurately crawl and render your JavaScript-dependent web app. If your content is rendered client-side, it will be resource-intensive for Google to crawl, and your site will underperform in search. No matter what you’ve heard to the contrary, if organic search is a valuable channel for your website, you need to make provisions for server-side rendering.
But server-side rendering is a concept which is frequently misunderstood…
“Implement server-side rendering”
This is a common SEO audit recommendation which I often hear thrown around as if it were a self-contained, easily-actioned solution. At best it’s an oversimplification of an enormous technical undertaking, and at worst it’s a misunderstanding of what’s possible/necessary/beneficial for the website in question. Server-side rendering is an outcome of many possible setups and can be achieved in many different ways; ultimately, though, we’re concerned with getting our server to return static HTML.
So, what are our options? Let’s break down the concept of server-side rendered content a little and explore our options. These are the high-level approaches which Google outlined at the aforementioned I/O conference:

Dynamic Rendering — Here, normal browsers get the ‘standard’ web app which requires client-side rendering while bots (such as Googlebot and social media services) are served with static snapshots. This involves adding an additional step onto your server infrastructure, namely a service which fetches your web app, renders the content, then returns that static HTML to bots based on their user agent (i.e. UA sniffing). Historically this was done with a service like PhantomJS (now deprecated and no longer developed), while today Puppeteer (headless Chrome) can perform a similar function. The main advantage is that it can often be bolted into your existing infrastructure.

Hybrid Rendering — This is Google’s long-term recommendation, and it’s absolutely the way to go for newer site builds. In short, everyone — bots and humans — get the initial view served as fully-rendered static HTML. Crawlers can continue to request URLs in this way and will get static content each time, while on normal browsers, JavaScript takes over after the initial page load. This is a great solution in theory, and comes with many other advantages for speed and usability too; more on that soon.
The latter is cleaner, doesn’t involve UA sniffing, and is Google’s long-term recommendation. It’s also worth clarifying that ‘hybrid rendering’ is not a single solution — it’s an outcome of many possible approaches to making static prerendered content available server-side. Let’s break down how a couple of ways such an outcome can be achieved.
Isomorphic/universal apps
This is one way in which you might achieve a ‘hybrid rendering’ setup. Isomorphic applications use JavaScript which runs on both the server and the client. This is made possible thanks to the advent of Node.js, which – among many other things – allows developers to write code which can run on the backend as well as in the browser.
Typically you’ll configure your framework (React, Angular Universal, whatever) to run on a Node server, prerendering some or all of the HTML before it’s sent to the client. Your server must, therefore, be configured to respond to deep URLs by rendering HTML for the appropriate page. In normal browsers, this is the point at which the client-side application will seamlessly take over. The server-rendered static HTML for the initial view is ‘rehydrated’ (brilliant term) by the browser, turning it back into a single page app and executing subsequent navigation events with JavaScript.
Done well, this setup can be fantastic since it offers the usability benefits of client-side rendering, the SEO advantages of server-side rendering, and a rapid first paint (even if Time to Interactive is often negatively impacted by the rehydration as JS kicks in). For fear of oversimplifying the task, I won’t go into too much more detail here, but the key point is that while isomorphic JavaScript / true server-side rendering can be a powerful solution, it is often enormously complex to set up.
So, what other options are there? If you can’t justify the time or expense of a full isomorphic setup, or if it’s simply overkill for what you’re trying to achieve, are there any other ways you can reap the benefits of the single page app model — and hybrid rendering setup — without sabotaging your SEO?
Prerendering/JAMstack
Having rendered content available server-side doesn’t necessarily mean that the rendering process itself needs to happen on the server. All we need is for rendered HTML to be there, ready to serve to the client; the rendering process itself can happen anywhere you like. With a JAMstack approach, rendering of your content into HTML happens as part of your build process.
I’ve written about the JAMstack approach before. By way of a quick primer, the term stands for JavaScript, APIs, and markup, and it describes a way of building complex websites without server-side software. The process of assembling a site from front-end component parts — a task a traditional site might achieve with WordPress and PHP — is executed as part of the build process, while interactivity is handled client-side using JavaScript and APIs.

Think of it this way: everything lives in your Git repository. Your content is stored as plain text markdown files (editable via a headless CMS or other API-based solution) and your page templates and assembly logic are written in Go, JavaScript, Ruby, or whatever language your preferred site generator happens to use. Your site can be built into static HTML on any computer with the appropriate set of command line tools before it’s hosted anywhere. The resulting set of easily-cached static files can often be securely hosted on a CDN for next to nothing.
I honestly think static site generators – or rather the principles and technologies which underpin them — are the future. There’s every chance I’m wrong about this, but the power and flexibility of the approach should be clear to anyone who’s used modern npm-based automation software like Gulp or Webpack to author their CSS or JavaScript. I’d challenge anyone to test the deep Git integration offered by specialist webhost Netlify in a real-world project and still think that the JAMstack approach is a fad.
 The popularity of static site generators on GitHub, generated using https://stars.przemeknowak.com
The popularity of static site generators on GitHub, generated using https://stars.przemeknowak.com
The significance of a JAMstack setup to our discussion of single page apps and prerendering should be fairly obvious. If our static site generator can assemble HTML based on templates written in Liquid or Handlebars, why can’t it do the same with JavaScript?
There is a new breed of static site generator which does just this. Frequently powered by React or Vue.js, these programs allow developers to build websites using cutting-edge JavaScript frameworks and can easily be configured to output SEO-friendly, static HTML for each page (or ‘route’). Each of these HTML files is fully rendered content, ready for consumption by humans and bots, and serves as an entry point into a complete client-side application (i.e. a single page app). This is a perfect execution of what Google termed “hybrid rendering”, though the precise nature of the pre-rendering process sets it quite apart from an isomorphic setup.
A great example is GatsbyJS, which is built in React and GraphQL. I won’t go into too much detail, but I would encourage everyone who’s read this far to check out their homepage and excellent documentation. It’s a well-supported tool with a reasonable learning curve, an active community (a feature-packed v2.0 was released in September), an extensible plugin-based architecture, rich integrations with many CMSs, and it allows developers to utilize modern frameworks like React without sabotaging their SEO. There’s also Gridsome, based on VueJS, and React Static which — you guessed it — uses React.
 Nike’s recent Just Do It campaign, which utilized the React-powered static site generator GatsbyJS and is hosted on Netlify.
Nike’s recent Just Do It campaign, which utilized the React-powered static site generator GatsbyJS and is hosted on Netlify.
Enterprise-level adoption of these platforms looks set to grow; GatsbyJS was used by Nike for their Just Do It campaign, Airbnb for their engineering site airbnb.io, and Braun have even used it to power a major e-commerce site. Finally, our friends at SEOmonitor used it to power their new website.
But that’s enough about single page apps and JavaScript rendering for now. It’s time we explored the second of our two key technologies underpinning PWAs. Promise you’ll stay with me to the end (haha, nerd joke), because it’s time to explore Service Workers.
3. Service Workers
First of all, I should clarify that the two technologies we’re exploring — SPAs and service workers — are not mutually exclusive. Together they underpin what we commonly refer to as a Progressive Web App, yes, but it’s also possible to have a PWA which isn’t an SPA. You could also integrate a service worker into a traditional static website (i.e. one without any client-side rendered content), which is something I believe we’ll see happening a lot more in the near future. Finally, service workers operate in tandem with other technologies like the Web App Manifest, something that my colleague Maria recently explored in more detail in her excellent guide to PWAs and SEO.
Ultimately, though, it is service workers which make the most exciting features of PWAs possible. They’re one of the most significant changes to the web platform in its history, and everyone whose job involves building, maintaining, or auditing a website needs to be aware of this powerful new set of technologies. If, like me, you’ve been eagerly checking Jake Archibald’s Is Service Worker Ready page for the last couple of years and watching as adoption by browser vendors has grown, you’ll know that the time to start building with service workers is now.

We’re going to explore what they are, what they can do, how to implement them, and what the implications are for SEO.
What can service workers do?
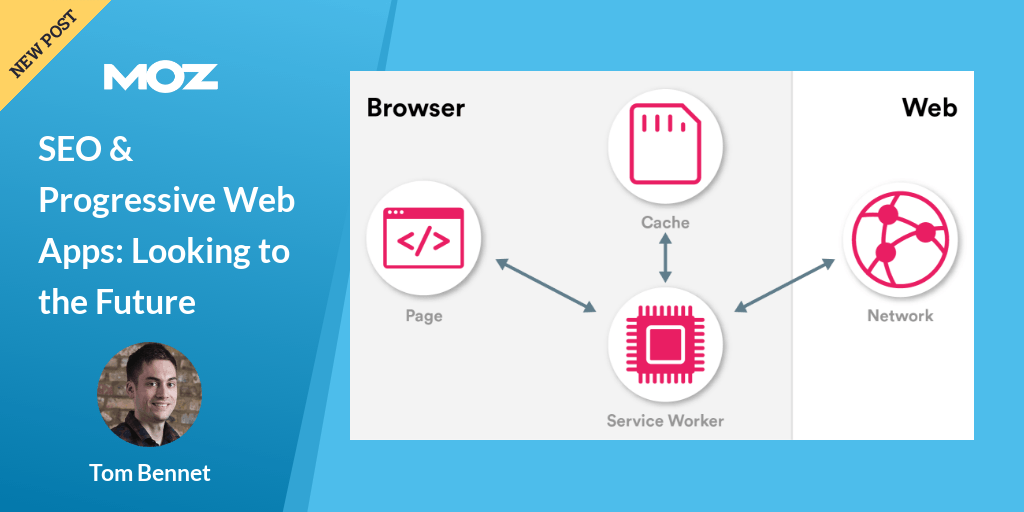
A service worker is a special kind of JavaScript file which runs outside of the main browser thread. It sits in-between the browser and the network, and its powers include:
Intercepting network requests and deciding what to do with them programmatically. The worker might go to network as normal, or it might rely solely on the cache. It could even fabricate an entirely new response from a variety of sources. That includes constructing HTML.
Preloading files during service worker installation. For SPAs this commonly includes the ‘app shell’ we discussed earlier, while simple static websites might opt to preload all HTML, CSS, and JavaScript, ensuring basic functionality is maintained while offline.
Handling push notifications, similar to a native app. This means websites can get permission from users to deliver notifications, then rely on the service worker to receive messages and execute them even when the browser is closed.
Executing background sync, deferring network operations until connectivity has improved. This might be an ‘outbox’ for a webmail service or a photo upload facility. No more “request failed, please try again later” – the service worker will handle it for you at an appropriate time.
The benefits of these kinds of features go beyond the obvious usability perks. As well as driving adoption of HTTPS across the web (all the major browsers will only register service workers on the secure protocol), service workers are transformative when it comes to speed and performance. They underpin new approaches and ideas like Google’s PRPL Pattern, since we can maximize caching efficiency and minimize reliance on the network. In this way, service workers will play a key role in making the web fast and accessible for the next billion web users.
So yeah, they’re an absolute powerhouse.
Implementing a service worker
Rather than doing a bad job of writing a basic tutorial here, I’m instead going to link to some key resources. After all, you are in the best position to know how deep your understanding of service workers needs to be.
The MDN Docs are a good place to learn more about service workers and their capabilities. If you’re already confident with the essentials of web development and enjoy a learn-by-doing approach, I’d highly recommend completing Google’s PWA training course. It includes a whole practical exercise on service workers, which is a great way to familiarize yourself with the basics. If ES6 and promises aren’t yet a part of your JavaScript repertoire, prepare for a baptism of fire.

They key thing to understand — and which you’ll realize very quickly once you start experimenting — is that service workers hand over an incredible level of control to developers. Unlike previous attempts to solve the connectivity conundrum (such as the ill-fated AppCache), service workers don’t enforce any specific patterns on your work; they’re a set of tools for you to write your own solutions to the problems you’re facing.
One consequence of this is that they can be very complex. Registering and installing a service worker is not a simple exercise, and any attempts to cobble one together by copy-pasting from StackExchange are doomed to failure (seriously, don’t do this). There’s no such thing as a ready-made service worker for your site — if you’re to author a suitable worker, you need to understand the infrastructure, architecture, and usage patterns of your website. Uncle Ben, ever the web development guru, said it best: with great power comes great responsibility.
One last thing: you’ll probably be surprised how many sites you visit are already using a service worker. Head to chrome://serviceworker-internals/ in Chrome or about:debugging#workers in Firefox to see a list.
Service workers and SEO
In terms of SEO implications, the most relevant thing about service workers is probably their ability to hijack requests and modify or fabricate responses using the Fetch API. What you see in ‘View Source’ and even on the Network tab is not necessarily a representation of what was returned from the server. It might be a cached response or something constructed by the service worker from a variety of different sources.

Credit: https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API
Here’s a practical example:
Head to the GatsbyJS homepage
Hit the link to the ‘Docs’ page.
Right-click – View Source
No content, right? Just some inline scripts and styles and empty HTML elements — a classic client-side JavaScript app built in React. Even if you open the Network tab and refresh the page, the Preview and Response tabs will tell the same story. The actual content only appears in the Element inspector, because the DOM is being assembled with JavaScript.
Now run a curl request for the same URL (https://www.gatsbyjs.org/docs/), or fetch the page using Screaming Frog. All the content is there, along with proper title tags, canonicals, and everything else you might expect from a page rendered server-side. This is what a crawler like Googlebot will see too.
This is because the website uses hybrid rendering and a service worker — installed in your browser — is handling subsequent navigation events. There is no need for it to fetch the raw HTML for the Docs page from the server because the client-side application is already up-and-running – thus, View Source shows you what the service worker returned to the application, not what the network returned. Additionally, these pages can be reloaded while you’re offline thanks to the service worker’s effective use of the cache.
You can easily spot which responses came from the service worker using the Network tab — note the ‘from ServiceWorker’ line below.

On the Application tab, you can see the service worker which is running on the current page along with the various caches it has created. You can disable or bypass the worker and test any of the more advanced functionality it might be using. Learning how to use these tools is an extremely valuable exercise; I won’t go into details here, but I’d recommend studying Google’s Web Fundamentals tutorial on debugging service workers.

I’ve made a conscious effort to keep code snippets to a bare minimum in this article, but grant me this one. I’ve put together an example which illustrates how a simple service worker might use the Fetch API to handle requests and the degree of control which we’re afforded:

The result:

I hope that this (hugely simplified and non-production ready) example illustrates a key point, namely that we have extremely granular control over how resource requests are handled. In the example above we’ve opted for a simple try-cache-first, fall-back-to-network, fall-back-to-custom-page pattern, but the possibilities are endless. Developers are free to dictate how requests should be handled based on hostnames, directories, file types, request methods, cache freshness, and loads more. Responses – including entire pages – can be fabricated by the service worker. Jake Archibald explores some common methods and approaches in his Offline Cookbook.
The time to learn about the capabilities of service workers is now. The skillset required for modern technical SEO has a fair degree of overlap with that of a web developer, and today, a deep understanding of the dev tools in all major browsers – including service worker debugging – should be regarded as a prerequisite.
4. Wrapping Up
SEOs need to adapt
Until recently, it’s been too easy to get away with not understanding the consequences and opportunities posed by PWAs and service workers.
These were cutting-edge features which sat on the periphery of what was relevant to search marketing, and the aforementioned wariness of many SEOs towards JavaScript did nothing to encourage experimentation. But PWAs are rapidly on their way to becoming a norm, and it will soon be impossible to do an effective job without understanding the mechanics of how they function. To stay relevant as a technical SEO (or SEO Engineer, to borrow another term from Mike King), you should put yourself at the forefront of these kinds of paradigm-shifting developments. The technical SEO who is illiterate in web development is already an anachronism, and I believe that further divergence between the technical and content-driven aspects of search marketing is no bad thing. Specialize!
Upon learning that a development team is adopting a new JavaScript framework for a new site build, it’s not uncommon for SEOs to react with a degree of cynicism. I’m certainly guilty of joking about developers being attracted to the latest shiny technology or framework, and at how rapidly the world of JavaScript development seems to evolve, layer upon layer of abstraction and automation being added to what — from the outside — can often seem to be a leaning tower of a development stack. But it’s worth taking the time to understand why frameworks are chosen, when technologies are likely to start being used in production, and how these decisions will impact SEO.
Instead of criticizing 404 handling or internal linking of a single page app framework, for example, it would be far better to be able to offer meaningful recommendations which are grounded in an understanding of how they actually work. As Jono Alderson observed in his talk on the Democratization of SEO, contributions to open source projects are more valuable in spreading appreciation and awareness of SEO than repeatedly fixing the same problems on an ad-hoc basis.
Beyond SEO
One last thing I’d like to mention: PWAs are such a transformative set of technologies that they obviously have consequences which reach far beyond just SEO. Other areas of digital marketing are directly impacted too, and from my standpoint, one of the most interesting is analytics.
If your website is partially or fully functional while offline, have you adapted your analytics setup to account for this? If push notification subscriptions are a KPI for your website, are you tracking this as a goal? Remembering that service workers do not have access to the Window object, tracking these events is not possible with ‘normal’ tracking code. Instead, it’s necessary to configure your service worker to build hits using the Measurement Protocol, queue them if necessary, and send them directly to the Google Analytics servers.
This is a fascinating area that I’ve been exploring a lot lately, and you can read the first post in my series of articles on PWA analytics over on the Builtvisible blog.
That’s all from me for now! Thanks for reading. If you have any questions or comments, please leave a message below or drop me a line on Twitter @tomcbennet.
Many thanks to Oliver Mason and Will Nye for their feedback on an early draft of this article.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]()
Read more: tracking.feedpress.it